高並發架構相關概念
1、QPS (每秒查詢率) : 每秒鐘請求或者查詢的數量,在互聯網領域,指每秒響應請求數(指HTTP請求)2、PV(Page View):綜合瀏覽量,即頁面瀏覽量或者點擊量,一個訪客在24小時內訪問的頁面數量
--注:同一個人瀏覽你的網站的同一頁面,只記做一次pv
3、吞吐量(fetches/sec) :單位時間內處理的請求數量(通常由QPS和並發數決定)
4、響應時間:從請求發出到收到響應花費的時間
5、獨立訪客(UV):一定時間範圍內,相同訪客多次訪問網站,只計算為1個獨立訪客
6、帶寬:計算帶寬需關注兩個指標,峰值流量和頁面的平均大小
7、日網站帶寬: PV/統計時間(換算到秒) * 平均頁面大小(kb)* 8
高並發解決方案
1、前端優化
(1) 減少HTTP請求[將css,js等合併]
(2) 添加異步請求(先不將所有數據都展示給用戶,用戶觸發某個事件,才會異步請求數據)
(3) 啟用瀏覽器緩存和文件壓縮
(4) CDN加速
(5) 建立獨立的圖片服務器(減少I/O)
2、服務端優化
(1) 頁面靜態化
(2) 並發處理
(3) 隊列處理
3、數據庫優化
(1) 數據庫緩存
(2) 分庫分錶,分區
(3) 讀寫分離
(4) 負載均衡
4、web服務器優化
(1) nginx反向代理實現負載均衡
(2) lvs實現負載均衡

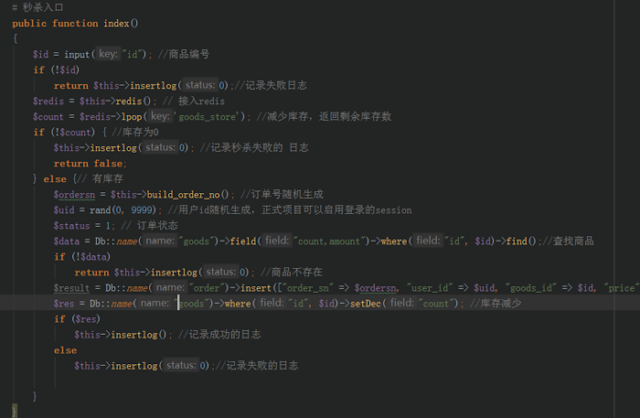
涉及搶購、秒殺、抽獎、搶票等活動時,為了避免超賣,那麼庫存數量是有限的,但是如果同時下單人數超過了庫存數量,就會導致商品超賣問題。
 採用ab壓力測試:
採用ab壓力測試:
-r 指定接收到錯誤信息時不退出程序
-t 等待響應的最大時間
-n 指定壓力測試總共的執行次數
-c 用於指定壓力測試的並發數
進入apache的bin目錄 cmd輸入下列分代碼
E:\phpstudy\Apache\bin>ab -r -t 60 -n 3000 -c 600 http://127.0.0.1/api/kill/index/id/1
結果


涉及搶購、秒殺、抽獎、搶票等活動時,為了避免超賣,那麼庫存數量是有限的,但是如果同時下單人數超過了庫存數量,就會導致商品超賣問題。
那麼我們怎麼來解決這個問題呢
高並發的情況下,正常邏輯寫的話數據庫的庫存會出現負數,對付這類問題有很多解決方案,我就不一一贅述,我這次用的是redis的隊列機制。

-r 指定接收到錯誤信息時不退出程序
-t 等待響應的最大時間
-n 指定壓力測試總共的執行次數
-c 用於指定壓力測試的並發數
進入apache的bin目錄 cmd輸入下列分代碼
E:\phpstudy\Apache\bin>ab -r -t 60 -n 3000 -c 600 http://127.0.0.1/api/kill/index/id/1
結果


